Method Overview
A two-stage reinforcement learning framework for human behavior simulation
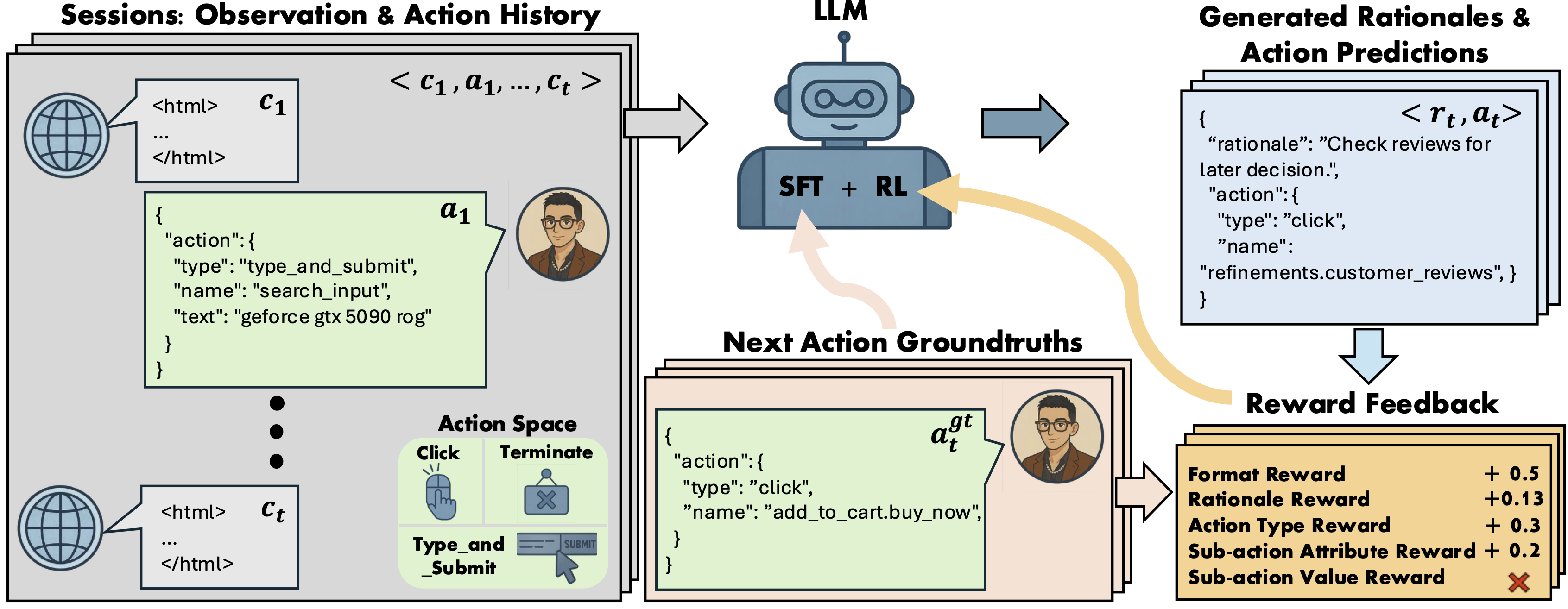
Figure 1: Overview of the Shop-R1 framework
Stage 1: Rationale Generation
Leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner, enabling the model to generate high-quality rationales.
Stage 2: Action Prediction
Hierarchical reward structure with difficulty-aware scaling evaluates both high-level action types and fine-grained sub-action details (attributes and values).
Reward Hacking Prevention
Difficulty-aware scaling mechanism prevents reward hacking by rewarding outputs proportionally to their difficulty, ensuring robust learning.
Reward Design Details
Binary Format Reward
Encourages the model to produce responses in a structured JSON format with two keys: rationale and action. A response earns a format reward of 0.5 if it is in valid JSON format; otherwise, it gains no format reward.
Self-Certainty Score (Rationale Reward)
Quantifies the model's confidence in its generated rationale by computing the KL divergence between the model's predictive distribution and a uniform distribution:
where N is the number of tokens, pij is the predicted probability of token i at position j, and Ui = 1/|V| is the uniform distribution. Higher values indicate greater certainty.
Hierarchical Action Reward
Replaces brittle binary signals with a hierarchical scheme that credits both coarse-grained action types and fine-grained sub-actions. This densifies the reward landscape, lifts the agent out of 'no-reward' plateaus, and makes reward hacking uneconomical.
| Action Type | Type Reward | Sub-action Attribute Reward | Text-Similarity Value Reward |
|---|---|---|---|
| terminate | 0.3 | None | None |
| click | 0.3 | +0.2 (if name ≠ ∅) | +DARS × ROUGE-L(name) |
| type_and_submit | 0.3 | +0.1 (if name ≠ ∅) +0.1 (if text ≠ ∅) |
+0.1 × ROUGE-L(name) +DARS × ROUGE-L(text) |
Table 4: Hierarchical reward schedule with Difficulty-Aware Reward Scaling (DARS).
Difficulty-Aware Reward Scaling (DARS)
Long-text sub-actions (e.g., button labels, search queries) are substantially harder since modern webpages can expose thousands of candidate elements. DARS amplifies rewards for correctly predicting these components, preventing reward hacking where the agent repeatedly selects trivial terminate actions to secure easy points.
Training Objective
Shop-R1 maximizes the combined reward signal while regularizing with KL divergence to a reference policy:
where v(a) is the action reward, s(r) is the self-certainty score, and α, β are hyperparameters controlling regularization strength.